摘要: 原標題:十款大模型挑戰高考作文:新考生DeepSeek奪冠,GPT第二,豆包和Kimi有點掉隊 6月7日,2025年全國高考拉開大幕。過去兩年,搜狐科技搜狐教育均聯合
原標題:十款大模型挑戰高考作文:“新考生”DeepSeek奪冠,GPT第二,豆包和Kimi有點掉隊
6月7日,2025年全國高考拉開大幕。過去兩年,搜狐科技&搜狐教育均聯合推出大模型參加高考系列策劃,今年我們繼續讓大模型挑戰高考作文。
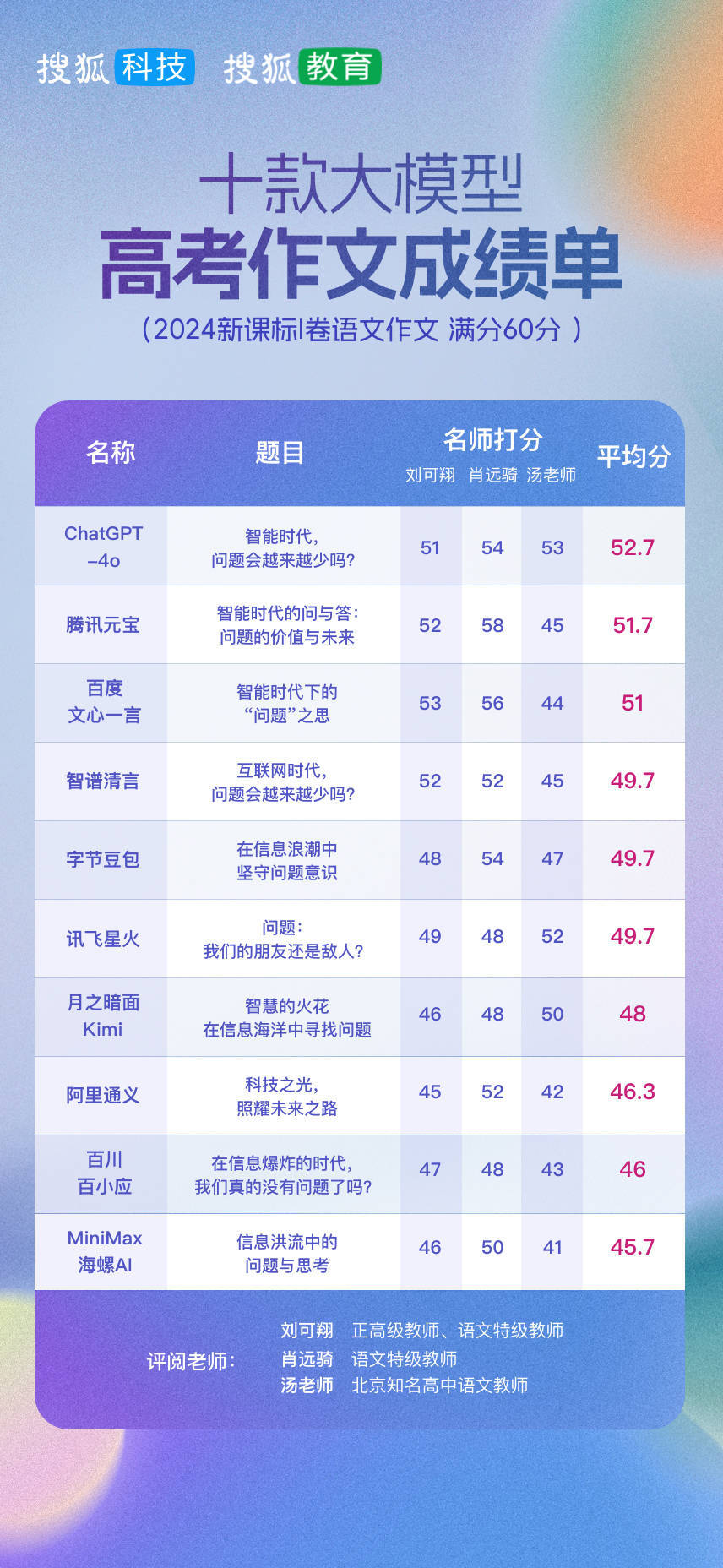
今年大模型考生還是10款模型,包括GPT-4.5、DeepSeek、通義千問、訊飛星火、文心一言、豆包、元寶、Kimi、學而思和商湯商量。今年高考作文試題我們選的是全國一卷,要求如下。
閱讀下面的材料,根據要求寫作。(60分)
他想要給孩子們唱上一段,可是心里直翻騰,開不了口。
——老舍《鼓書藝人》(見全國一卷閱讀II)
假如我是一只鳥,
我也應該用嘶啞的喉嚨歌唱
——艾青《我愛這土地》
我要以帶血的手和你們一一擁抱,
因為一個民族已經起來
——穆旦《贊美》
以上材料引發了你怎樣的聯想和思考?請寫一篇文章。
要求:選準角度,確定立意,明確文體,自擬標題;不要套作,不得抄襲;不得泄露個人信息;不少于800字。
在10款大模型答題結束后,我們邀請到四位高中語文教學名師,分別對這些作文進行了盲審盲評,并根據平均分進行成績排序。
結果顯示,DeepSeek以54.25分的平均分奪得第一;GPT-4.5、騰訊元寶則各自以53分、51.75的成績分列第二、第三,百度文心一言平均分達到51,這四款模型則是此次得分均超過50分的考生。
今年是DeepSeek首次參加高考作文測評,并直接獲得第一。北京市特級教師、北師大二附中語文老師何杰,以及北京中學語文高級教師,北京市骨干教師房樹洪均對DeepSeek所寫作文打出了55的高分,河南省骨干教師、信陽大別山高級中學語文老師陳光則給這篇文章打了54分。
何杰老師認為,該文審題準確,認識深刻,從表達者深沉的情感入手,探討表達者聲音的實質與特點,顯示出寫作者對于文藝學知識的諳熟與深刻認知,成文有感染力。房樹洪老師則表示,該文對概念的界定客觀準確,為下文的論證奠定了較好的基礎,論據較充實。
這很大程度得益于DeepSeek模型的最新升級——最近更新的推理模型R1-0528,其思考更深,推理更強,測評表現在國內所有模型中首屈一指,并接近OpenAI的o3、谷歌Gemini-2.5-Pro等國際頂尖模型。
同時,更新后的模型文本能力也有所升級。DeepSeek此前提到,在創意寫作方面,R1-0528針對議論文、小說、散文等文體進行了進一步優化,能夠輸出篇幅更長、結構內容更完整的長篇作品,同時呈現出更加貼近人類偏好的寫作風格,并降低了幻覺率。正高級教師、語文特級教師劉可翔就提到,該文語言表達較有韻味。
GPT-4.5依然是此次十款大模型考生中唯一的外國考生,其是OpenAI今年2月發布的最新大模型版本。當時OpenAI聲稱GPT-4.5是“迄今規模最大、知識最豐富的模型”,能更精準理解用戶意圖,擁有更高的情商。
在搜狐科技過往兩年的高考作文評測中,OpenAI的GPT模型均位居第一,此次則被國產模型DeepSeek撼動,排名掉到了第二,平均分成績53分。
房樹洪老師對GPT-4.5所寫的作文點評到:面對困難與痛苦時竭力發出真實而向上的聲音,闡釋清晰,層次分明,縱橫交錯,但有些地方有點局限于“聲音”本身,并打出了56的高分。
劉可翔老師則給出54分,認為該文立意準確,邏輯性較強,能結合現實寫作,引導人們怎么做,但深刻性方面還有待提高。
騰訊元寶的表現依然不錯,獲得51.75的平均分,位居第三,其在去年則排名第二,僅次于GPT-4o。該產品基于騰訊自研的混元大模型,其在高質量的內容創作、數理邏輯、代碼生成、多輪對話等性能表現優越。
房樹洪老師給元寶作文打出了55分,認為其由表及里,從具象到抽象,逐步展現了對問題的深入思考,指出了“聲音”的不用表現形式。何杰老師認為,對題目要求理解正確且獨特,舉例與引述豐富,體現出豐富的語言積累,但文章論述不夠深入。
百度文心一言的表現也還不錯,排名則從去年的第三落到第四,這兩次成績都是51分。也就是說,如果沒有黑馬DeepSeek今年殺出,今年高考作文評測前三名和去年一致,均為OpenAI的GPT模型、騰訊元寶和百度文心一言,可以說頭部陣營非常穩固。
去年均有參與評測的阿里通義千問、訊飛星火、字節豆包、月之暗面Kimi,今年成績集中在47-49分之內;其中通義千問進步比較明顯,排名從去年的第八升到了今年的第五,豆包和Kimi排名和得分均有所下降。
商湯商量和學而思則位于最后兩名,得分均在43左右。需要指出的是,學而思采用九章大模型進行評測,其主要是面向數學領域打造的大模型,可能并不擅長語文。
2024年十款大模型參加高考作文的成績單
整體來看,此次十款大模型在今年高考作文的表現比較懸殊,最高分和最低分的分值差達11分(去年為7分),顯示模型之間能力差距有所擴大。
同時,值得注意的是,此次評測除GPT-4.5、學而思外,其余模型均開啟推理模式。因而在作答過程中,這些考生會先對題目材料和要求進行分析確認,像真正參加高考的學生們一樣去審題并思考如何下筆。
過往兩次評測中,不少模型出現的缺少題目、字數不夠等問題,這次基本沒有出現(僅學而思出現字數不夠的情況),評分老師在點評中多次提到文章審題準確。這也在一定程度上反映出,推理能力的提高對提升模型的文本能力有促進作用。
這其中GPT-4.5是個例外,其并不具備類似推理模型o1或DeepSeek的鏈式推理功能,但其采用了無監督學習,用于增強詞匯知識和直覺,并增強了推理能力,能以更低延遲提供更高水平的推理能力,因此取得不錯表現。
另外,從寫作風格來看,此前兩次高考作文測試中,不少大模型在內容結構上喜歡用首先、其次、另外、最后、綜上所述等進行上下文的起承轉合,總體給人感覺稍顯呆板。
這次測試,多數模型已放棄了這種方式,表明模型的表達風格更為自然,更加擬人。不少模型還有較多的舉例論證或引用,但部分模型在內容深度上還有待加強。













新教育 · 新觀察 · 新視點
